In SharePoint 2010 there is the capability to enable incoming mail directly to a list or a calendar. This is a very useful feature for your SharePoint 2010 environment as it can enable your users to send documents directly to a list and send meeting requests to a shared SharePoint calendar. The benefits of sending meeting requests to a shared SharePoint calendar is that your users may have a requirement to show the meetings that are taking place for a certain project or office depending on how your site is being used.
Before I go through the steps in how to set this up, you need to be aware that the shared Calendar in SharePoint is not stored in Exchange. It is stored in SharePoint along with are any attachments that are sent to the shared Calendar.
Please note that I am not going to include the steps of creating the Directory Management Service which will enable SharePoint to be able to write to Active Directory. I will be covering creating the SMTP Service on the SharePoint servers, configuring the SMTP Send Connector in Exchange, configuring Incoming Mail in Central Administration and enabling incoming mail in your list/calendar. This will include ensuring that your mail address will be using a friendly name e.g ‘@mail.contoso.com’. If you wish to find out more about how to set up Directory Management Service with SharePoint then I can recommend SharePoint George’s blog.
Step 1: Configuring the SMTP Service on the SharePoint Server(s)
The first step is to set up the SMTP Service. This needs to be set up on your SharePoint servers that you have designated to handle the mail (eg web front end servers).
SharePoint 2010 requires the SMTP Service to be running, so you need to go to Features in Server Manager and install the SMTP Service on your Windows Server 2008 R2 server.

Once installed you will get the results screen to show a successful install.
Now open the IIS 6.0 Management Tools from Administrative Tools and configure the SMTP Service.
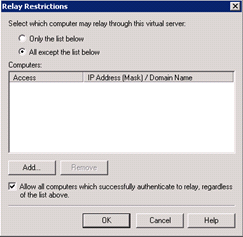
Go to the properties of the ‘SMTP Virtual Server’, click on the General tab and enable logging for troubleshooting. Then click on the access tab and enable “Anonymous access”. On the same tab, go to “Relay” and select the settings in the screenshot below.

Now go to messages and set the relevant settings for your organisation, an example is in the screenshot below. Then go to the Delivery tab and you can make the settings as you desire. I have gone for the default settings.


On the Security tab add the service account this is running the SharePoint 2010 timer service. This is the SharePoint service account that will be accessing the SMTP service to collect the mail. Ensure the same service account has read/write permissions to the mailroot folder (C:\InetPub\Mailroot). This will enable mail to be deleted once the timer service has collected the mail item.

Your SMTP Service will now look like the image below.
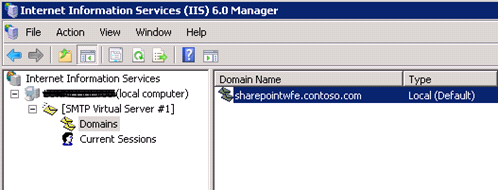
The domain name is automatically set as the ‘servername.domain’. The domain name is what is specified in the incoming email settings in Central Administration, so we need to ensure this is a friendly name for the users. In IIS 6.0 change the domain name to a friendly name e.g ‘mail.contoso.com’. This is important as the same name will need to be specified as the name of the Address Space in the SMTP Send Connector and the Incoming Email settings in Central Administration. So it needs to be a functional and user friendly name. Nb: The Domain Name does not need to be registered in DNS as a host record or MX record as Exchange will handle the address space.

Step 2: Configuring the SMTP connector to send mail to SharePoint.
The next stage is to enable mail to be routed to your SharePoint farm from Exchange. This is configured in the Exchange Management Console using the SMTP Send Connector. The SMTP Send Connector effectively routes mail to the relevant SharePoint Servers hosting the SMTP service (configured in step 1). Before you create the SMTP Send Connector, in DNS create an MX record for each of your SharePoint servers hosting the SMTP Service. The MX records needs to have the same naming convention for each SharePoint Server. An example is below:
MX Record ‘sharepointmail.contoso.com’ mapped to ‘sharepointwfe01.contoso.com’, with cost of ’10’
MX Record ‘sharepointmail.contoso.com’ mapped to ‘sharepointwfe02.contoso.com’, with cost of ’10’.
In Exchange Management Console, create a SMTP Send Connector with a useful name e.g ‘SharePoint 2010 Incoming Mail’.

In the address space, specify the address space name that you wish to use. E.g ‘mail.contoso.com’ with a cost of ’50’.
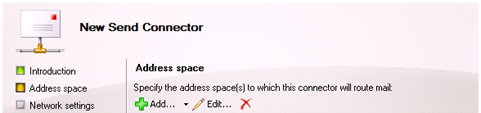
In the Network Settings, specify to use ‘Route Mail through the following smart hosts’ and add the name of the smart host which is the name of the MX Records. E.g ‘sharepointmail.contoso.com’.
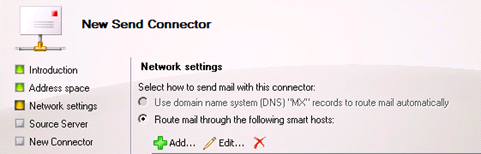
In the Source Server section, add the relevant Mail servers that you wish to associate to the Send Connector.
Nb: If you have two or more servers and want to send mail to one server first, then specify the server1 with a cost of 10 and the server2 with a cost of 20. Mail will go to server1 first and then to server2 second if server1 is unavailable. This will need experience of the Exchange and AD as the cost is associated to the MX Record.
Step 3: Configuring SharePoint to use Incoming Mail
The penultimate stage is to configure SharePoint with the relevant incoming email settings and enable incoming mail on your document library or calendar. To do this, go to Central Administration, System Settings and Configure Incoming Mail. Turn the feature on and specify’ Advanced’ rather than ‘automatic’.

Specify ‘No’ for the Directory Management Service

Specify the mail server display name as ‘mail.contoso.com’. This is the same name as the SMTP Send Connector and the Domain Name in your SMTP Service so it is important to keep the naming convention consistent. This will be the name space for all your email address that you create for your document library or calendar.

Specify the drop folder as ‘C:\inetpub\mailroot\drop’. This is the folder where Exchange will drop the email\calendar item. The item will then be picked up from the SharePoint 2010 Timer Service and inserted into the relevant document library or calendar.

Step 4: Enable Incoming Mail on your Calendar or Document Library
The final stage is to now enable incoming mail on your calendar or document library. This can be done by going to the ‘List Settings’ of your doc library\calendar and under communications select ‘Incoming Email Settings’ and in the incoming email section type the name of your email address. For this example I have used ‘calendar@mail.contoso.com’. This will ensure that all meeting requests that are sent to this address will be added to the calendar.

If you would like to monitor the mail progress then I would recommend monitoring the drop folder for the first couple of test emails\appointments to ensure the item is dropped in that directory and collected by the timer service. Please note that the timer job ‘Microsoft SharePoint Foundation Incoming E-Mail’ checks the folder every couple of minutes to collect mail.