
I discovered a strange issue with my SharePoint 2010 Farm that uses FAST Search 2010 as its search infrastructure. The issue related to my content source continually running a full crawl rather than an incremental even though the crawl schedules were set correctly. There was nothing obvious to say there was a problem as the full crawl completed but took longer than expected and all other content sources looked to run correctly using an incremental.
I started out troubleshooting the environment and going through the main health checks detailed below:
- SQL: Check to see if there are any locks on the crawler and content dbs
- SharePoint Crawl Servers: Check to see if the CPU or memory is maxing out of running consistently high.
- FAST Search: Check to see if the index is healthy by running “Indexerinfo status -a” on the FAST Servers” and see if the number documents that are active match the total. Ensure to check both the primary and backup indexer in your results from running the command in powershell for fast search.
- FAST Search: Check through the logs in %FAST SEARCH%\var\log and in particular the ‘configserver.log’ and ‘all.log’ on the FAST admin server.
After checking through the main troubleshooting points, you can run a perfmon trace to get more information, but instead I ran through my install notes and also checked through the details of Kristopher Loranger’s blog ‘FAST Search for SharePoint 2010 Crawler Troubleshooting’ to uncover the issue.
From the ‘configserver.log’ file I found numerous entries relating to the error below.
“the ping call resulted in the following exception: socket.error: [Errno 10060] The operation timed out.”
This namely pointed to a communication error between the fast search admin server and the indexing servers. From my install notes and the blog from Kristopher Loranger, a communication error would usually relate to a TCP offloading issue on the FAST Search Servers. TCP Offloading should be disabled on your FAST Search and SharePoint servers as it doesn’t work effectively with IPSEC.
I checked the TCP offloading settings using the command “netsh int ip show global, and the settings were correct. Chimney Offload State = Disabled.
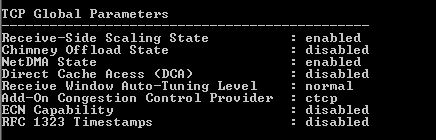
Then I checked the offloading settings on the network card layer… This is where the problem lay. All the entries with ‘Offload’ were enabled. This was changed when the VM was moved to a different host so definitely one to watch for when migrating servers.

So to resolve the issue, change all entries with ‘Offload’ in the property name and reboot all the fast servers. Ensure you disable your crawls before following through with this task.
The Microsoft Blog on TCP Offloading is really useful going through the detailed steps in TCP offloading for your FAST Search environment.
